Building Dynamic Queries with the CFBD GraphQL API

Have you ever wanted more granular control over how you query data from CFBD? By more granular control, I mean dynamic filtering and sorting, querying related pieces of data in one query, and even the ability to specify which specific fields you want to be queried.
What about better real-time data support in the form of subscriptions? The REST API offers a few live endpoints that require constant polling, but I'm talking about being able to create a specific data query, subscribing to that query, and your own code being notified in real time when the data in that query changes. And this is far beyond the few live REST endpoints offered today. Imagine being able to subscribe to betting line updates, for example.
The experimental CFBD GraphQL API can enable you to do all of this and it is available to Patreon Tier 3 subscribers starting today. I put emphasis on the word experimental. It does not yet have full access to the entire CFBD data catalog, but it does incorporate a decent amount as of right now:
- Team information
- Conference information
- Historical team/conference associations
- Historical and live game data (scores, Elo ratings, excitement index, weather, media information)
- Historical and live betting data
- Recruiting data
- Transfer data
- NFL Draft history
Things that are not currently included but will be added over time:
- Drive and play data
- Basic game, player, and season stats
- Advanced game, player, and season stats
Neither of these lists are exhaustive.
If you would like to learn and see some examples, then read on.
What is GraphQL?
GraphQL is a query language for APIs. Its central premise is that it defines a data model as a "graph" of attributes and relationships. When interfacing with such an API, you specify exactly which data you need, how it should be filtered, how it should be sorted, and it has paging abilities to grab data in batches. This is much different than a traditional REST API where you are given a concrete set of REST endpoints with discrete query parameters and a rigid data model response.
So how does it work differently from working with REST endpoints? The funny thing is, it basically is a REST endpoint. Unlike traditional REST APIs where you would likely have many different endpoints scattered across multiple different HTTP operations (e.g. GET, POST, PUT, etc), GraphQL exposes a single POST endpoint, usually named just graphql. You submit a POST request to that endpoint and the request body contains all the information about what you are trying to do and what data you want to receive back, all in GraphQL syntax.
Here is a simple GraphQL query using the new CFBD GraphQL endpoint:
query gamesQuery {
game(where: { season: { _eq: 2024 } }, orderBy: { startDate: ASC }) {
id
season
seasonType
week
startDate
homeTeam
homeClassification
homeConferece
homePoints
awayTeam
awayClassification
awayConferece
awayPoints
lines {
provider {
name
}
spread
}
}
}
GraphQL offers three types of operations: queries for querying data, mutations for changing data, and subscriptions for subscribing to data updates. The above example is a query named gamesQuery. The query part is important since it tells the API that we are querying for data, but the gamesQuery part is completely arbitrary. In fact, we could have completely left off query gamesQuery and the API would implicitly know we are trying to query data.
The interesting stuff starts on line 2. There is a game object that is made available in the graph and we are telling the API that we want to query these objects. We are also including some filtering and sorting on this line. We are telling the API to return games from the 2024 season and to sort by the start_date property.
Let's look at the filter a little more closely: where: { season: { _eq: 2024 } }. We are using an equal operator (_eq) to filter on the 2024 season, but there are many more operators. For example, we could use _gt if we wanted to query on seasons greater than a specific year. We can also combine filters. Let's say we wanted to query games from the 2024 season, but only in weeks 1, 3, and 5. We could do something like this: where: { season: { _eq: 2024 }, week: { _in: [1, 3, 5] } }. We'll look at some more complex scenarios later on.
We also have an ordering statement: orderBy: { startDate: ASC }. This tells the API to sort the results by the startDate field in ascending order. Similar to filters, we can combine these if we want to sort by multiple fields. And we can specify whether we want to sort in ascending or descending order on each field.
As we continue past line 2, you can see that we are also able to specify which game object fields we would like returned back in the query. On line 16, we introduce another object in the graph via the lines property. We have a whole gameLines object that we could write a separate query on. However, we also have a relationship between games and game lines via the lines property. Because of this, we can tell the API to return any game lines associated with each game object. We can also specify which properties we want to be returned in these nested relationships. Notably, you'll see that we have another relationship nested within a relationship, as the provider object has a relationship with the lines object. provider provides information on the sportsbook that provides the game line.
We've gotten this far, so we should probably look at the data that gets returned by this query.
...
{
"id": 401635525,
"season": 2024,
"seasonType": "regular",
"week": 1,
"startDate": "2024-08-24T16:00:00",
"homeTeam": "Georgia Tech",
"homeClassification": "fbs",
"homeConferece": "ACC",
"homePoints": 24,
"awayTeam": "Florida State",
"awayClassification": "fbs",
"awayConferece": "ACC",
"awayPoints": 21,
"lines": [
{
"provider": {
"name": "ESPN Bet"
},
"spread": 10.5
},
{
"provider": {
"name": "DraftKings"
},
"spread": 11.5
},
{
"provider": {
"name": "Bovada"
},
"spread": 10.0
}
]
},
...
As you can see, it matches the format and fields that we specified in the query. Let's write another query with a little bit more complexity. I want to query the most exciting games of the past 10 seasons as measured by the CFBD Excitement Index metrics. My query would look like this:
query excitementQuery {
game(
where: { season: { _gte: 2014 }, excitement: { _isNull: false } }
orderBy: { excitement: DESC }
limit: 100
) {
id
season
seasonType
week
startDate
homeTeam
homeClassification
homeConferece
homePoints
awayTeam
awayClassification
awayConferece
awayPoints
excitement
}
}
I'm writing this article right at the start of the 2024 season, so I've updated my filter, where: { season: { _gte: 2014 }, excitement: { _isNull: false } } to query all games starting with the 2014 season where the excitement field is not null or empty. I also included a sort clause, orderBy: { excitement: DESC }, because I want to sort by excitement in descending order so that the most exciting games are returned at the top. Lastly, I specified a limit of 100 results (limit: 100) because I only want the top 100 most exciting games.
Here are the partial results of that query:
{
"data": {
"game": [
{
"id": 401282177,
"season": 2021,
"seasonType": "regular",
"week": 1,
"startDate": "2021-09-05T00:00:00",
"homeTeam": "South Alabama",
"homeClassification": "fbs",
"homeConferece": "SBC",
"homePoints": 31,
"awayTeam": "Southern Mississippi",
"awayClassification": "fbs",
"awayConferece": "CUSA",
"awayPoints": 7,
"excitement": 21.5355699358
},
{
"id": 401418780,
"season": 2022,
"seasonType": "regular",
"week": 9,
"startDate": "2022-10-29T21:00:00",
"homeTeam": "Central Arkansas",
"homeClassification": "fcs",
"homeConferece": "ASUN",
"homePoints": 64,
"awayTeam": "North Alabama",
"awayClassification": "fcs",
"awayConferece": "ASUN",
"awayPoints": 29,
"excitement": 16.5218277643
},
{
"id": 401416599,
"season": 2022,
"seasonType": "regular",
"week": 2,
"startDate": "2022-09-10T22:00:00",
"homeTeam": "Miami (OH)",
"homeClassification": "fbs",
"homeConferece": "MAC",
"homePoints": 31,
"awayTeam": "Robert Morris",
"awayClassification": "fcs",
"awayConferece": null,
"awayPoints": 14,
"excitement": 15.5860040950
},
...
]
}
}
In the next few sections, we'll dive into how to query from the CFBD GraphQL API using Insomnia and Python.
Using the CFBD GraphQL API with Insomnia
If you haven't seen my post on using Insomnia with the CFBD API, then be sure to check it out. Insomnia is by far the best tool for experimenting with different APIs. Not only is it fantastic for experimenting with traditional REST calls, but it also has really great GraphQL support. This section of the guide assumes you are familiar with Insomnia and have it set up.
So let's go ahead and open up Insomnia. You are going to create a new request just like you normally would, but this time select "GraphQL Request" from the dropdown.
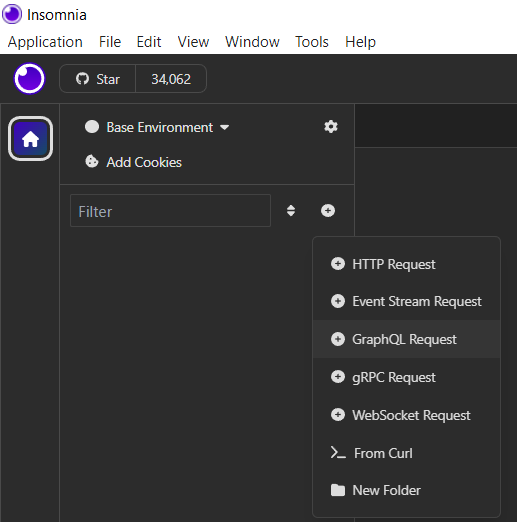
The new request should look really similar to a POST request and even be labeled as such. Before we fill in the URL, we're going to add our Auth details. Select "Bearer Token" from the Auth dropdown.
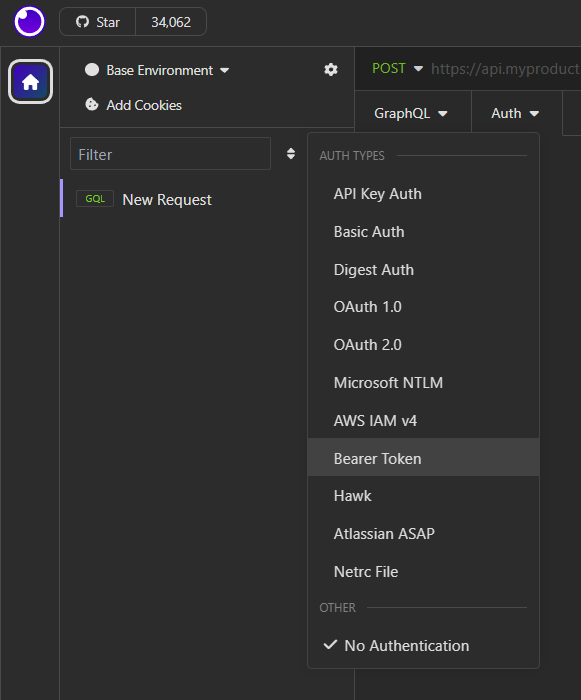
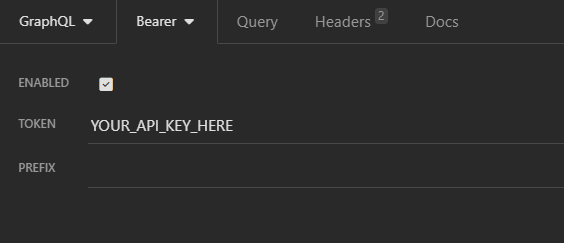
In the Token field, fill in your API key. It will be the same API key you use on the CFBD API. There is no need to add a Bearer prefix or anything else. Just paste in your key.
Now go ahead and fill out the URL: https://graphql.collegefootballdata.com/v1/graphql. After pasting that in, click on "schema" and select "Refresh Schema". Also, make sure that "Automatic Fetch" is enabled.
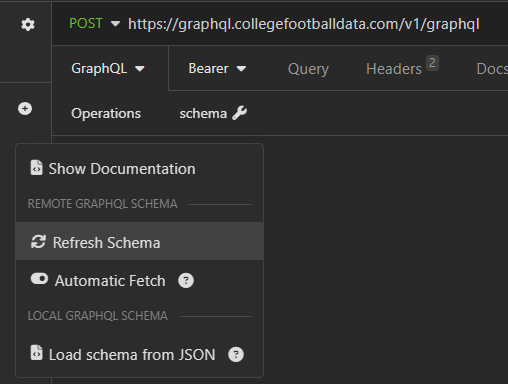
Click on "Show Documentation" from the same dropdown will open up a documentation side panel on the right. From the side panel, click on query_root to see which queries are available.
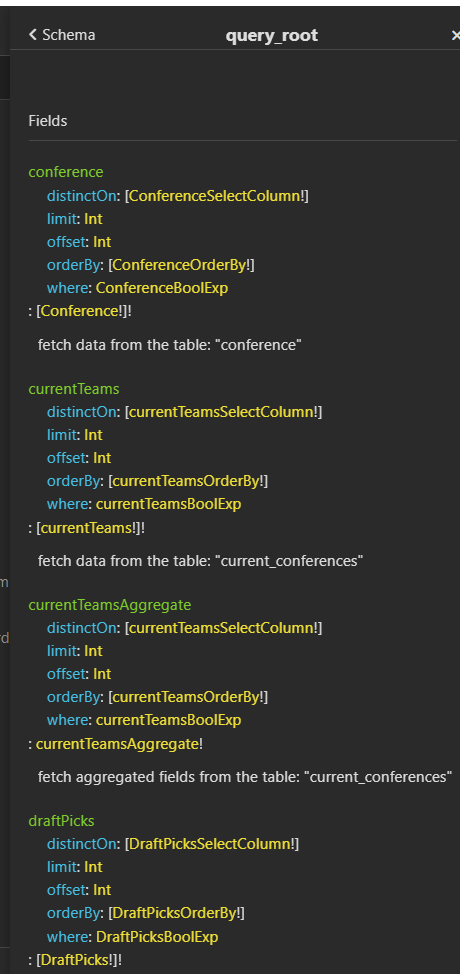
These docs are interactive, you feel free to click around to learn about the different queries and types. However, these docs aren't even necessary to get going but I did want to point them out because it's still a very nice feature.
Go ahead and click on the GraphQL tab, click inside of the code body, and then hit Ctrl+Space. The code editor has full autocomplete capabilities.
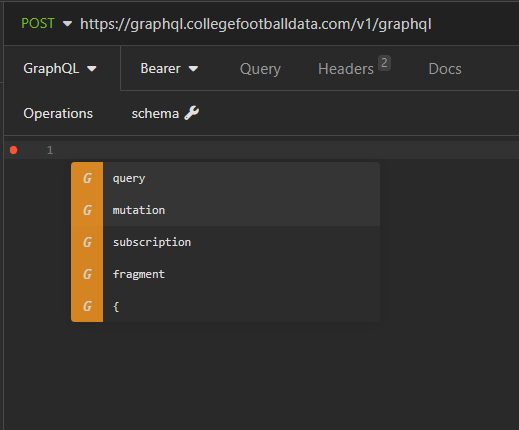
As you type out queries, you can use this functionality to guide you without even needing to really know or reference the documentation.
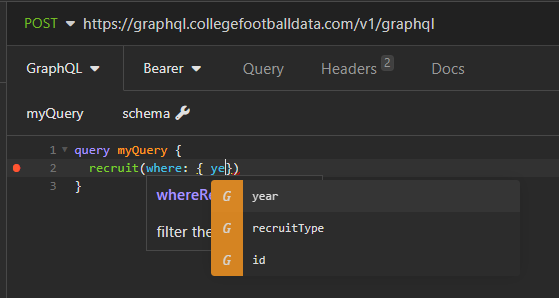
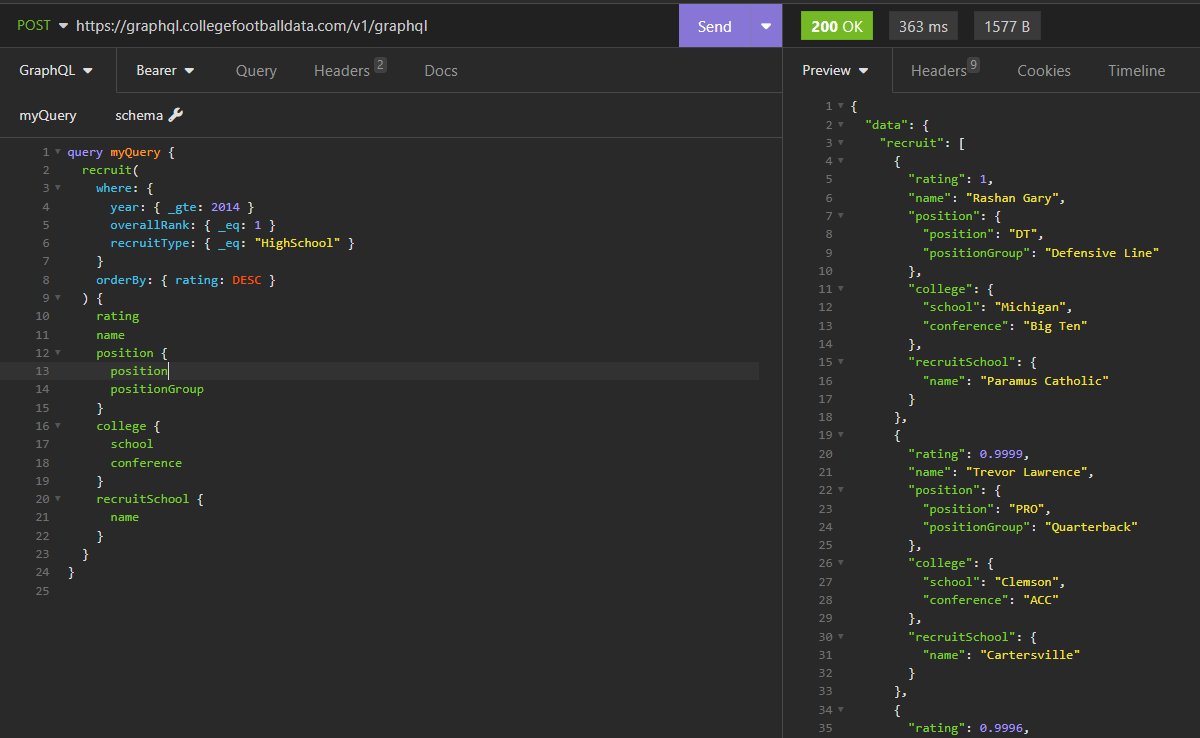
Let's query some recruiting data. I want to query every #1 overall high school recruit since the 2014 cycle. Additionally, I want to order by overall composite rating, with the highest ratings at the top. My query would look like this:
query myQuery {
recruit(
where: {
year: { _gte: 2014 }
overallRank: { _eq: 1 }
recruitType: { _eq: "HighSchool" }
}
orderBy: { rating: DESC }
) {
rating
name
position {
position
positionGroup
}
college {
school
conference
}
recruitSchool {
name
}
}
}
Feel free to mess around with the query. Pick whatever fields you want to return and tweak the filters and the sorts if you desire to do so. Once you're satisfied, go ahead and submit. This is what my query returned back:
I'm actually curious about my hometown. I come from a really tiny town in northern Ohio called Huron. I would like to know if there have been any legitimate recruits in the recruiting service era to hail from there. When I played (early aughts), the recruiting services where just becoming a thing and we didn't really have any FBS-level players. We had a really great TE named Jim Fisher who played at Michigan and would have fit the bill, but he was a year or two before my time and before Rivals and Scout got big.
Anyway, here's the query I drew up.
query myQuery {
recruit(
where: {
recruitType: { _eq: "HighSchool" }
hometown: { city: { _eq: "Huron" }, state: { _eq: "OH" } }
}
orderBy: { rating: DESC }
) {
stars
ranking
positionRank
rating
name
position {
position
positionGroup
}
college {
school
conference
}
recruitSchool {
name
}
hometown {
city
state
}
}
}
And here are the results:
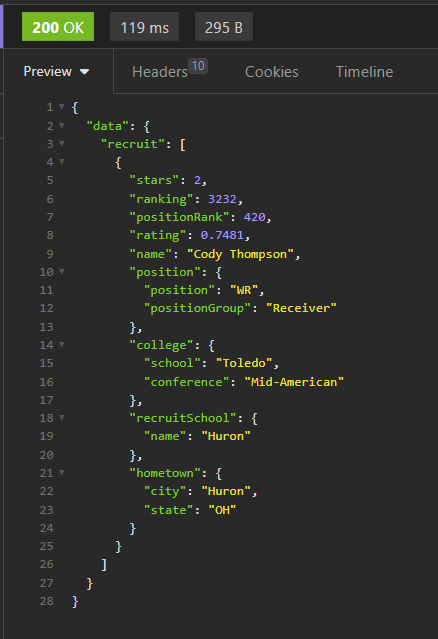
We've had one lone 2* WR who ended up at Toledo. Way to go, Cody!
I can slightly modify this query if I want to filter historical recruits by any geographic region. Like if I wanted to query all-time recruits from the state of Alaska:
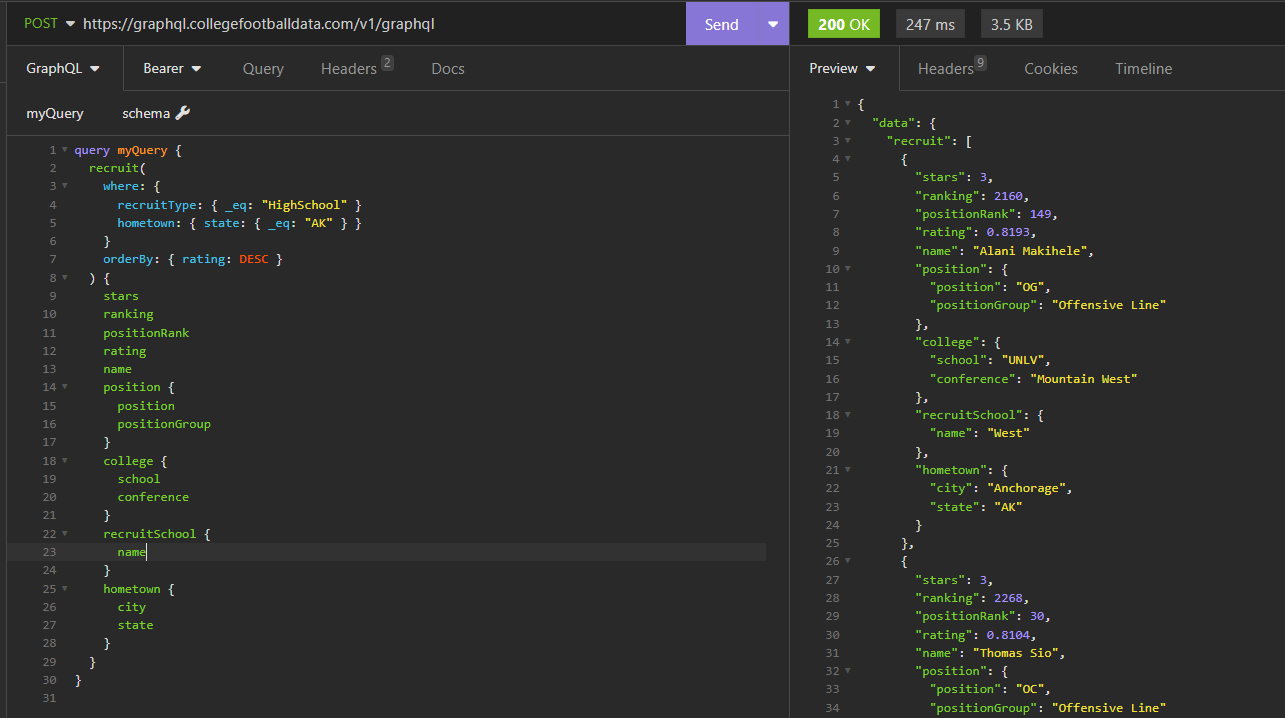
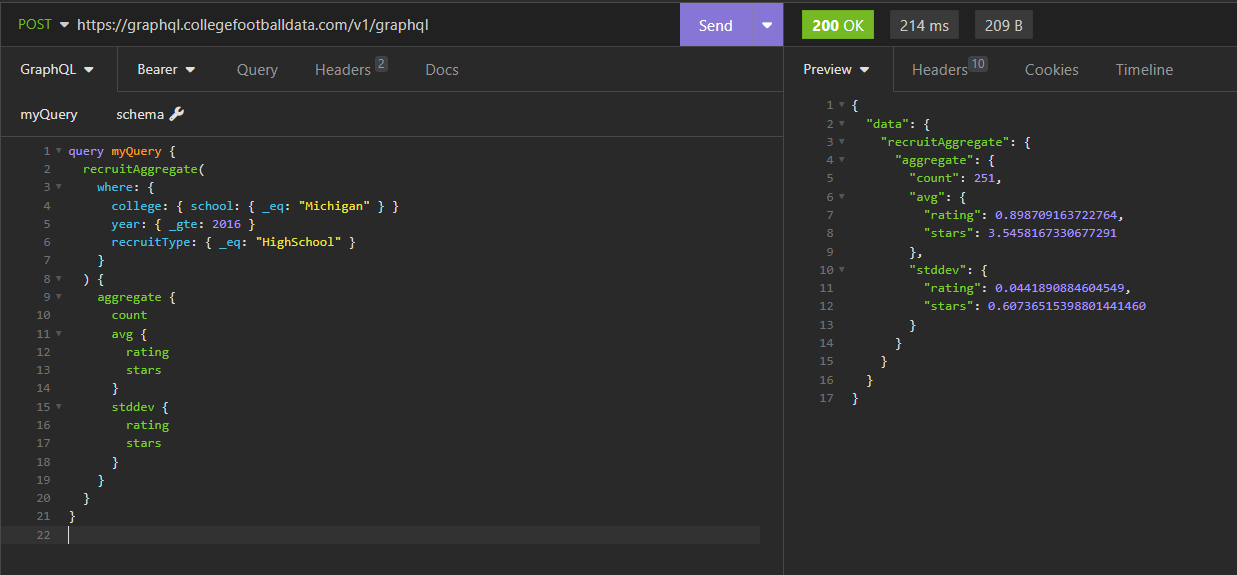
We can even do aggregates. For example, if I wanted to find mean stars and ratings and their respective standard deviations for all Michigan recruits since 2016, I could run something like the below:
query myQuery {
recruitAggregate(
where: {
college: { school: { _eq: "Michigan" } }
year: { _gte: 2016 }
recruitType: { _eq: "HighSchool" }
}
) {
aggregate {
count
avg {
rating
stars
}
stddev {
rating
stars
}
}
}
}
Here are the results:
Using the CFBD GraphQL API with Python
I will preface this section by stating that you can interface with GraphQL APIs using just about any programming. It all amounts to a basic HTTP POST request after all. If you can make an HTTP request, you can make a GraphQL request. That all said, some tools and libraries make things much easier. If I'm being honest, TypeScript/JavaScript is the best ecosystem for working with GraphQL. Much like Python is largely unparalleled when it comes to libraries available for data science and machine learning, the TypeScript/JavaScript ecosystem is unparalleled when it comes to libraries and utilities for GraphQL.
However, I recognized that a large majority of CFBD users are working in Python. And frankly, Python is probably still the correct choice for you if you are working in data and analytics. Luckily, Python does have its own set of libraries for working with GraphQL.
GQL is one of the more popular packages for interfacing with GraphQL APIs in Python. We can install it from PyPI:
pip install "gql[all]"
Or if you're using Conda:
conda install gql-with-all
For the duration of this section, I will be running my Python code out of a Jupyter notebook. However, you should be able to run this same code even if you aren't running in Jupyter.
We'll start off by importing packages from GQL:
from gql import Client, gql
from gql.transport.aiohttp import AIOHTTPTransport
Next, we will create a transport around the CFBD GraphQL URL and GraphQL client around this transport.
transport = AIOHTTPTransport(
url="https://graphql.collegefootballdata.com/v1/graphql",
headers={ "Authorization": "Bearer YOUR_API_KEY_HERE"}
)
client = Client(transport=transport, fetch_schema_from_transport=True)
Note that this is also where you need to configure your API. Replace YOUR_API_KEY_HERE in the above snippet with the API key you use for the CFBD API. Notice that we do need to supply a "Bearer " prefix here.
I'm going to mirror the previous section on using Insomnia. If you skipped it, I highly recommend checking it out. I find it's usually easier to design GraphQL queries in Insomnia prior to putting them into Python code.
Executing the same query, which grabs all #1 overall high school recruits since 2014 and sorting in descending order of Composite rating looks like this:
query = gql(
"""
query myQuery {
recruit(
where: {
year: { _gte: 2014 }
overallRank: { _eq: 1 }
recruitType: { _eq: "HighSchool" }
}
orderBy: { rating: DESC }
) {
rating
name
position {
position
positionGroup
}
college {
school
conference
}
recruitSchool {
name
}
}
}
"""
)
result = await client.execute_async(query)
result
This is what the output looks like in my Jupyter notebook.
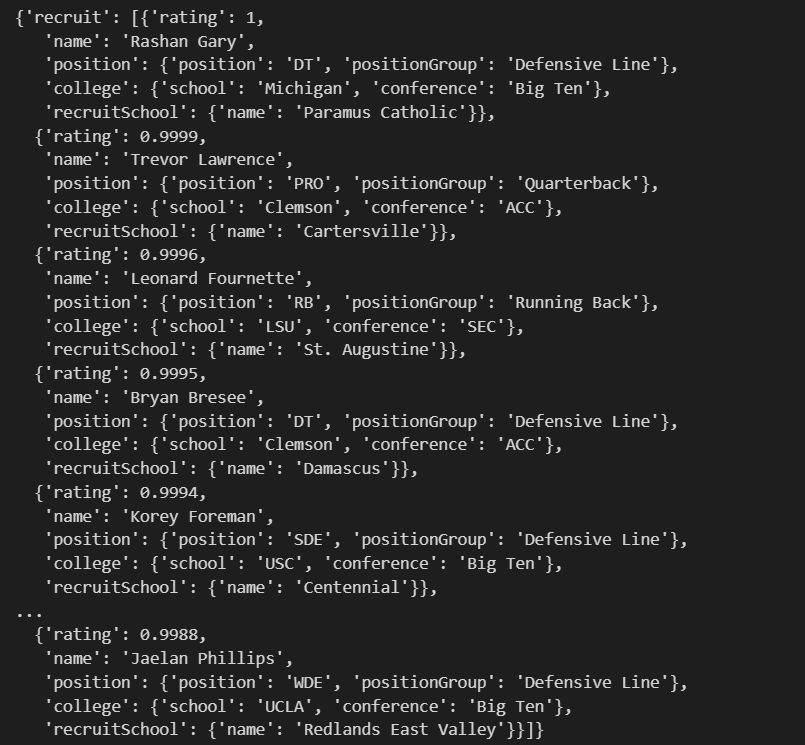
We can run type(result) to see that result is a dict. It should be relatively easy to loop through this result and format it to our liking.
We can flatten all of the dicts to make them easier to put into a DataFrame:
formatted = [dict(rating=r['rating'], name=r['name'], college=r['college']['school'], position=r['position']['position']) for r in result['recruit']]
formatted
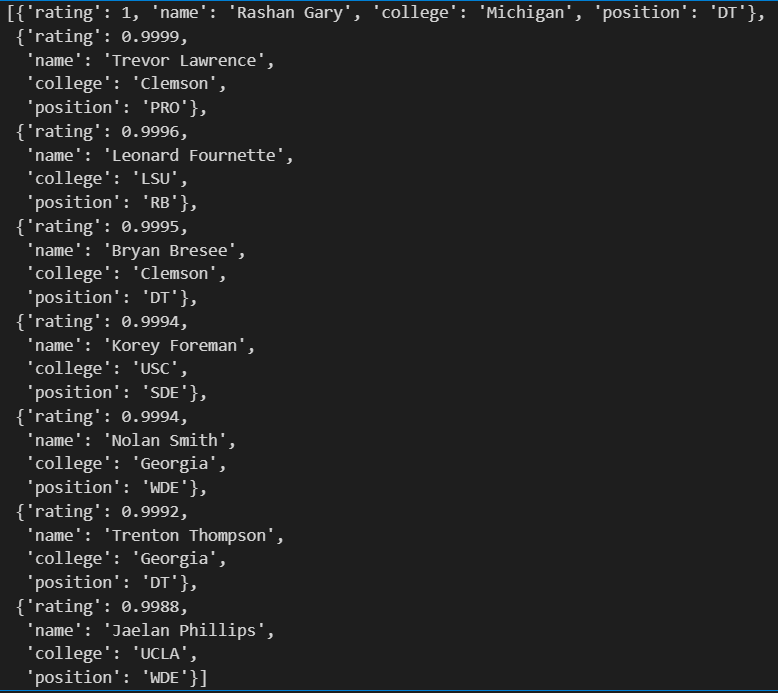
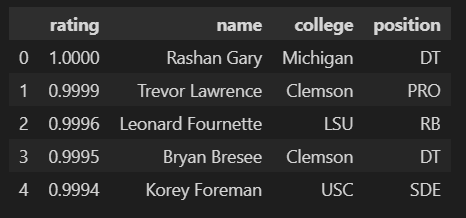
We can now easily get this into a pandas DataFrame.
import pandas as pd
df = pd.DataFrame(formatted)
df.head()
Let's run another query. This time I am going to query Michigan's historical entries in the AP poll, sorted with the most recent appearances first.
query = gql(
"""
query myQuery {
pollRank(
where: {
team: { school: { _eq: "Michigan" } }
poll: { pollType: { name: { _eq: "AP Top 25" } } }
}
orderBy: [
{ poll: { season: DESC } }
{ poll: { seasonType: DESC } }
{ poll: { week: DESC } }
]
) {
rank
points
firstPlaceVotes
poll {
season
seasonType
week
pollType {
name
}
}
}
}
"""
)
result = await client.execute_async(query)
result
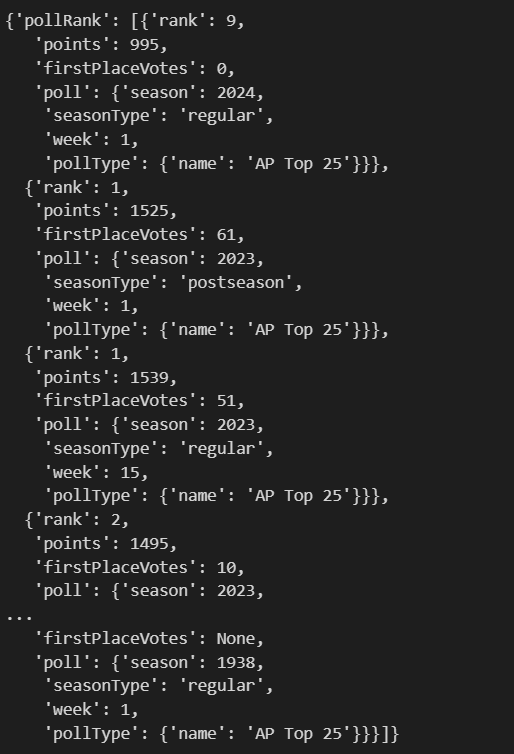
We can again flatten this and load it into a DataFrame if we desire, but I'll leave that up to you.
Conclusion
I hope that illustrates the power of GraphQL and what it can do for you. It allows for much more flexibility and fewer restrictions. I get requests all the time for querying the data in different ways or different formats or allowing different types of query parameters. This can be very difficult to keep up with and maintain in a traditional REST API, but is easy work when working with GraphQL.
Again, this is available to you if you are a Patreon Tier 3 subscriber. Got to Patreon if you are interested in checking it out. I will reiterate that this is very experimental right now. If there are pieces of data available in the REST API that you would like to see here, I am in the process of adding more and more data. Another huge benefit is real-time GraphQL subscriptions, but I'll save that for a future post. If you end up checking it out, let me know what you think!